Airwallex’s core promise is to make global payments feel local. The company invests heavily in local payment rails (ACH, SEPA, Faster Payments), multi-currency accounts, and a unified internal ledger powering collections, FX, payouts, and cards. From the outside, this looks like a clean, modern alternative to traditional banks.
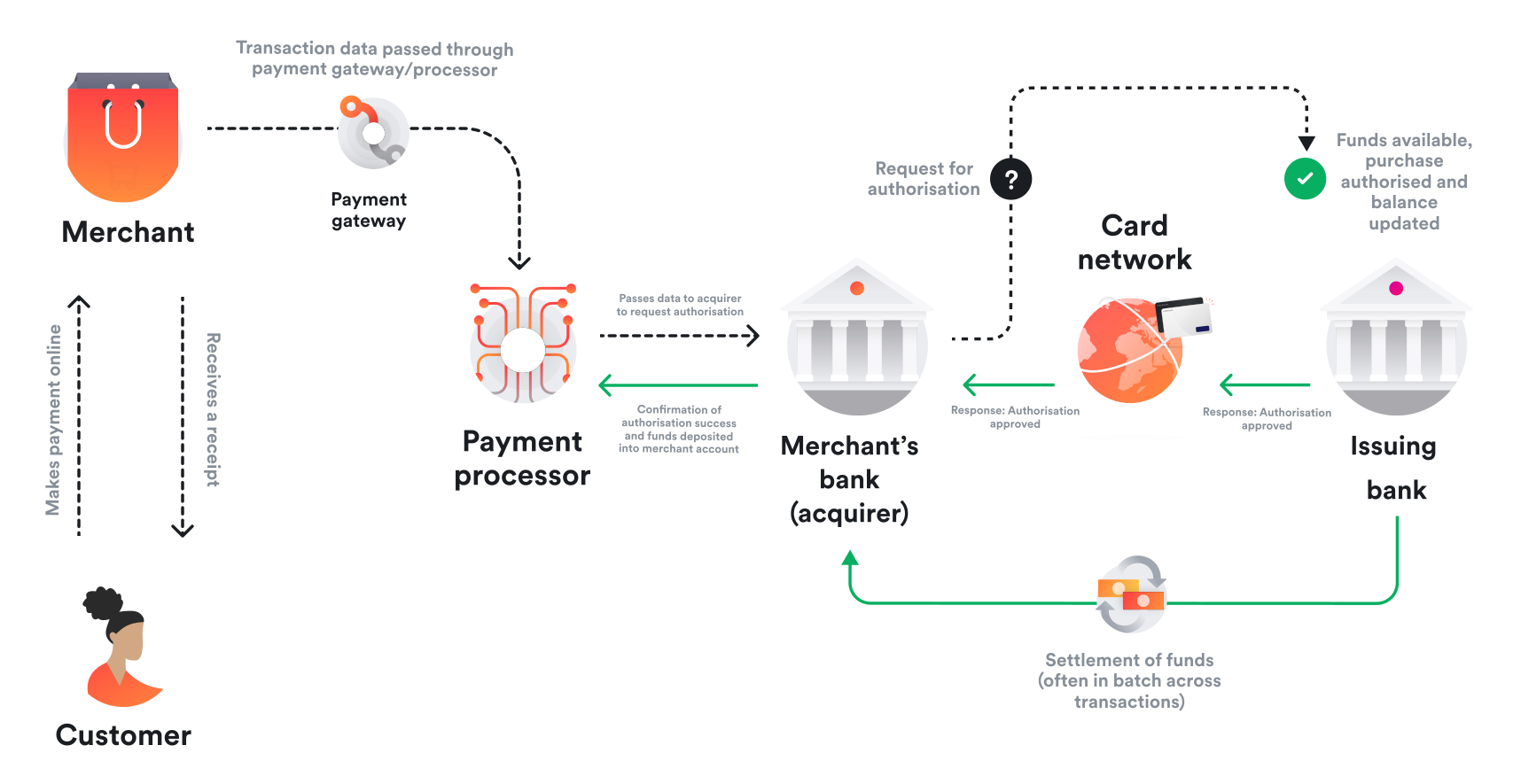
From the inside, I learned that global payments are a constant negotiation between ideal architecture and real-world constraints. As Airwallex scaled rapidly across regions and customer segments, the gap between “supported corridors” and “reliable corridors” became a product problem that sat at the intersection of compliance, engineering, operations, and customer trust.
I owned the product work to close that gap for SWIFT-based payouts.
The Context: When Local Rails Are Not Enough
As Airwallex expanded into more markets and served larger, more complex customers, a recurring question surfaced across sales, onboarding, and support conversations:
“Can I pay suppliers in this country?”
For many destinations, the answer was yes through local rails. But for long-tail corridors, specific currencies, and certain regulatory environments, SWIFT was the only viable option.
This created a genuine product dilemma. Not supporting SWIFT meant incomplete global coverage, which directly cost enterprise deals. But supporting SWIFT naively risked higher failure rates, opaque timelines, and significant operational overhead. Enterprise customers needed coverage guarantees, not best-effort transfers.
The problem was initially unclear because the failures were distributed across corridors and surfaced in different teams. Sales saw it as a coverage gap. Support saw it as a ticket volume problem. Engineering saw it as a formatting issue. Nobody owned the full picture.
The Problem: SWIFT Unlocks Reach but Introduces Risk
SWIFT is powerful precisely because it is universal, but that universality comes at a cost. From a product perspective, SWIFT payments introduced four compounding challenges: corridor-specific formatting and regulatory requirements that changed by destination, higher rejection and repair rates compared to local rails, limited transparency once a payment left the Airwallex system, and increased support load from delayed or failed transfers.
Unlike local rail failures, which surface immediately with clear error codes, SWIFT failures were slow to diagnose, expensive to fix, and difficult for customers to self-correct. A single failed SWIFT payment could generate multiple support tickets, manual investigation across banking partners, and days of customer uncertainty.
To put this in perspective: I analyzed one month of SWIFT-related support tickets and found that payment formatting errors and missing regulatory fields accounted for over 60% of all SWIFT failures. These were preventable errors that were only caught after the payment had already entered the correspondent banking network, where correction is slow and costly.
The question was never whether to support SWIFT. The question was how to support it without eroding trust in the Airwallex experience.
Reframing the Challenge: SWIFT as a Product Problem
The obvious approach would have been to expand corridor coverage first and address failures reactively. I rejected that path because it would have scaled the support burden proportionally with volume, making SWIFT increasingly expensive to operate as adoption grew.
Instead, I reframed the work as a product quality and reliability problem. Rather than treating SWIFT as “legacy infrastructure that just needs more coverage,” I positioned it as a system where the cost of downstream failure far exceeds the cost of upstream prevention.
The guiding principle became:
Move failure upstream. If a payment is going to fail, it should fail immediately, before entering the SWIFT network, with a clear explanation that the customer can act on.
This reframing changed the conversation across teams. Engineering shifted from “how do we route more payments” to “how do we validate before routing.” Compliance shifted from post-failure review to pre-submission surfacing. Support shifted from reactive investigation to proactive self-serve enablement.
Strategic Decision Framework
Decision Tree: Support SWIFT or Not
| Path | Customer Outcome | Business Impact | Decision |
|---|---|---|---|
| Do not support SWIFT | Limited corridor coverage | Lost enterprise deals | Not acceptable |
| Support SWIFT without validation | Higher failure rate and support load | Trust erosion | Not acceptable |
| Support SWIFT with smart validation | Higher success rate with manageable ops | Scalable coverage | Chosen |
Quantified Impact Model
I modeled the impact using a simple reliability equation so we could set clear targets.
First-pass success = 1 - failure rate Support load = payment volume * failure rate * tickets per failure Failure cost = support load * cost per ticket + delay penalties
Targets for v1 validation:
- Reduce failure rate by 30% in top corridors
- Cut average support handling time by 25%
- Achieve 60% self-serve correction rate for fixable errors
Risk-Reward Analysis: Validation Strictness
| Validation Level | Reward | Risk | Decision Logic |
|---|---|---|---|
| Too strict | Lower downstream failure | Higher false blocks | Apply only to high-risk corridors |
| Balanced | Stable success rate | Moderate ops load | Default policy |
| Too loose | Higher conversion | High failure and support cost | Avoid |
Metrics-Driven Iteration
Once the baseline was set, I treated validation rules as experiments. We A/B tested strictness by corridor, tuned error messaging for self-serve correction, and monitored three rollback triggers: corridor-level failure spikes, conversion drops beyond 3%, and support ticket volume rising above target. This kept optimization grounded in reliability, not instinct.
What We Built: Validation as a Growth Strategy
The core of the SWIFT expansion was not simply adding more countries or banks. It was designing intelligent validation that balanced coverage, compliance, and conversion without requiring any single team to own the full complexity alone.
1. Corridor-Aware Validation
SWIFT requirements vary widely by destination. A payment to India requires different beneficiary fields than a payment to Brazil, and intermediary bank requirements change depending on the currency pair. We introduced dynamic validation rules based on destination country and currency, required beneficiary and bank details, and intermediary bank constraints. This prevented payments that were technically valid in format but operationally doomed to fail at the correspondent bank level.
2. Bank Identifier Intelligence
We strengthened checks around BIC/SWIFT code structure and country alignment, deprecated or unsupported bank routing, and IBAN validation where applicable. One key insight from analyzing historical failures was that passing format checks does not guarantee acceptance downstream. A structurally valid BIC code could still route to a bank that no longer processes the relevant currency, causing a silent failure days later. We built logic to catch these cases before submission.
3. Compliance Embedded in the Product Flow
Certain corridors require explicit purpose-of-payment codes or regulatory context that varies by jurisdiction. The previous workflow handled this after submission: a payment would fail, support would identify the missing field, and the customer would resubmit. I worked directly with the Compliance team to map these requirements by corridor and surface them during payment creation. This required negotiation because Compliance initially preferred post-submission review for audit trail reasons. We reached alignment by ensuring that pre-submission surfacing still generated a complete audit log, satisfying their requirements while reducing customer friction.
4. Actionable Failure Feedback
SWIFT error messages from correspondent banks are notoriously opaque (“FIELD 59 INVALID” tells a customer nothing useful). I analyzed the historical failure corpus, grouped errors into fixable versus non-fixable categories, and worked with the UX team to map bank response codes into customer-understandable messages with clear next steps. This turned support-heavy failures into self-serve corrections, allowing customers to fix and resubmit without opening a ticket.
The Hardest Tradeoff: Precision vs. Conversion
The biggest product tension was deciding how strict validations should be. Overly strict validation blocks legitimate payments, frustrates customers, and reduces conversion. Overly loose validation pushes failures downstream, generates support tickets, and erodes trust over time.
I made three explicit prioritization decisions to navigate this tension. First, we targeted high-frequency failure modes rather than trying to cover every edge case, because the top 10 failure patterns accounted for over 70% of SWIFT rejections. Second, we only blocked payments for errors that customers could realistically fix through self-serve correction, such as missing fields or incorrect bank codes. For ambiguous cases where we were uncertain whether validation was correct, we surfaced warnings rather than hard blocks. Third, we prioritized validations with the highest operational leverage, meaning the rules that would eliminate the most support tickets per implementation effort.
This approach allowed us to improve reliability without materially harming conversion. We tracked both metrics weekly and maintained a 3% conversion drop as the hard ceiling for any individual validation rule. Any rule that exceeded that threshold was either relaxed or converted from a block to a warning.
Impact
The validation system delivered measurable results across the metrics we defined upfront.
| Metric | Before | After | Change |
|---|---|---|---|
| SWIFT first-pass success rate | Baseline | +30% improvement in top corridors | Fewer payments entering repair workflows |
| Support ticket volume (SWIFT) | Baseline | 25% reduction | Less manual investigation per failed payment |
| Self-serve correction rate | Near zero | 60%+ for fixable errors | Customers resolved issues without support |
| Average support handling time | Baseline | 25% reduction | Clearer error context reduced diagnosis time |
Beyond efficiency metrics, the business impact was strategic. SWIFT coverage expanded to corridors where no local rails existed, which directly unblocked enterprise deals that required global payout guarantees. Enterprise customers could consolidate global payouts on Airwallex rather than maintaining separate banking relationships per region.
Most importantly, SWIFT shifted from being a source of unpredictable failures to being a controlled fallback rail with known reliability characteristics. The operations team could forecast support load by corridor, and the sales team could confidently quote coverage without worrying about downstream failure rates.
What I Learned
This project shaped how I think about platform products in regulated, high-stakes environments.
- Infrastructure becomes product the moment customers feel its failure. Payments infrastructure is invisible when it works. The product challenge is ensuring that the failure experience is just as designed as the success experience.
- Coverage unlocks revenue; reliability unlocks trust. Enterprise customers do not adopt a payments platform for the corridors that already work well. They adopt it because they trust it will handle the corridors that are hard.
- Validation is a judgment call, not a checklist. Every validation rule is a product decision that trades off conversion against reliability. Treating validation as purely an engineering concern ignores the business consequences of both false blocks and false passes.
- The best payments experience is the one where nothing goes wrong. Unlike consumer products where delight comes from visible features, payments products succeed by making complexity invisible. The highest-impact work often produces the least visible output.
Closing Reflection
Local rails power scale. SWIFT powers reach. The real product challenge is knowing when and how to combine them without compromising trust.
This project reinforced a principle I carry into every product decision: in constrained, regulated environments, the highest-leverage work is not building more features. It is designing systems that fail safely, surface errors clearly, and give users confidence that the system is working on their behalf even when something goes wrong.
That balance between ideal systems and messy reality is where the most meaningful product work lives.